
Selected publications are listed below. For a full list, see my Google Scholar profile.
Laplace Approximation For Bayesian Tensor Network Kernel Machines
Summary
Uncertainty estimation is essential for robust decision-making in the presence of ambiguous or out-of-distribution inputs. Gaussian Processes (GPs) are classical kernel-based models that offer principled uncertainty quantification and perform well on small- to medium-scale datasets. Alternatively, formulating the weight space learning problem under tensor network assumptions yields scalable tensor network kernel machines. However, these assumptions break Gaussianity, complicating standard probabilistic inference. This raises a fundamental question: how can tensor network kernel machines provide principled uncertainty estimates? We propose a novel Bayesian Tensor Network Kernel Machine (LA-TNKM) that employs a (linearized) Laplace approximation for Bayesian inference. A comprehensive set of numerical experiments shows that the proposed method consistently matches or surpasses Gaussian Processes and Bayesian Neural Networks (BNNs) across diverse UCI regression benchmarks, highlighting both its effectiveness and practical relevance.
Laplace Approximation For Tensor Train Kernel Machines In System Identification
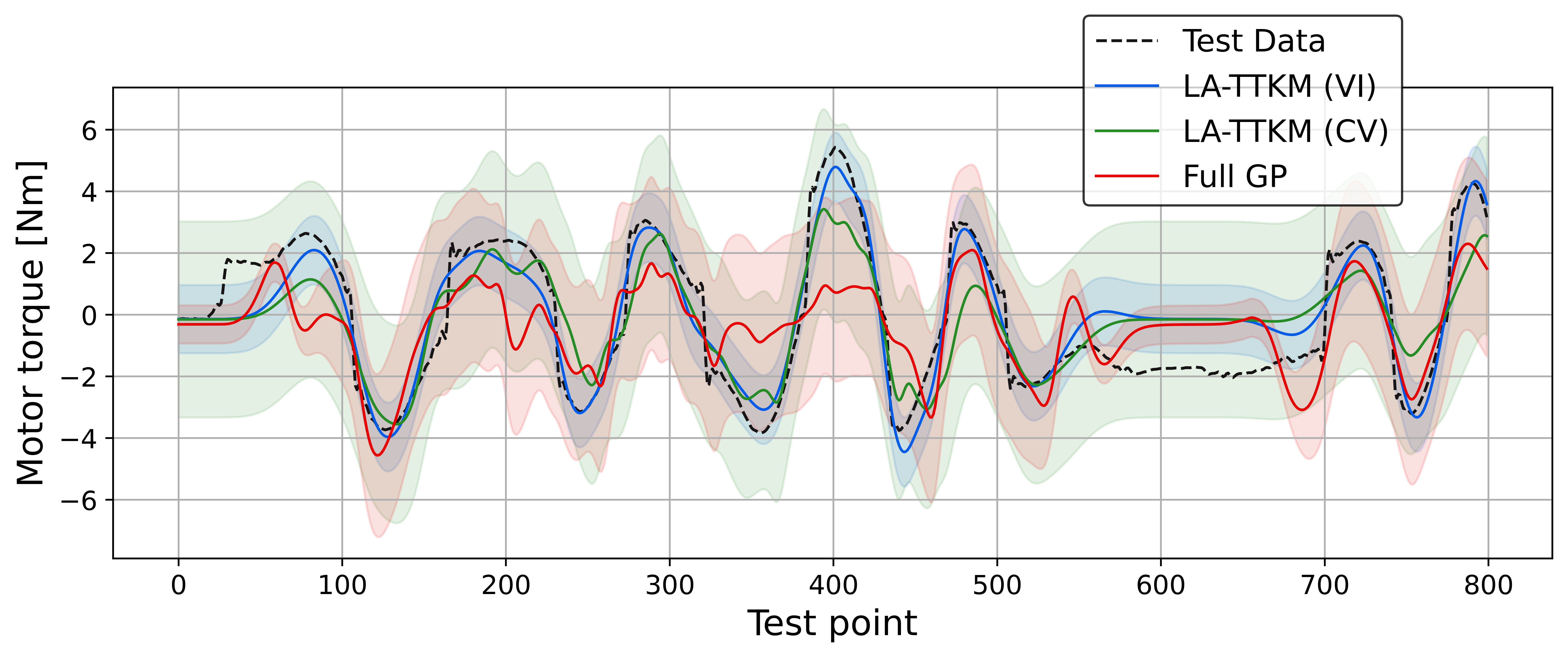
Summary
To address the scalability limitations of Gaussian process (GP) regression, several approximation techniques have been proposed. One such method is based on tensor networks, which utilizes an exponential number of basis functions without incurring exponential computational cost. However, extending this model to a fully probabilistic formulation introduces several design challenges. In particular, for tensor train (TT) models, it is unclear which TT-core should be treated in a Bayesian manner. We introduce a Bayesian tensor train kernel machine that applies Laplace approximation to estimate the posterior distribution over a selected TT-core and employs variational inference (VI) for precision hyperparameters. Experiments show that core selection is largely independent of TT-ranks and feature structure, and that VI replaces cross-validation while offering up to 65x faster training. The method’s effectiveness is demonstrated on an inverse dynamics problem.
Tensor Network Based Feature Learning Model
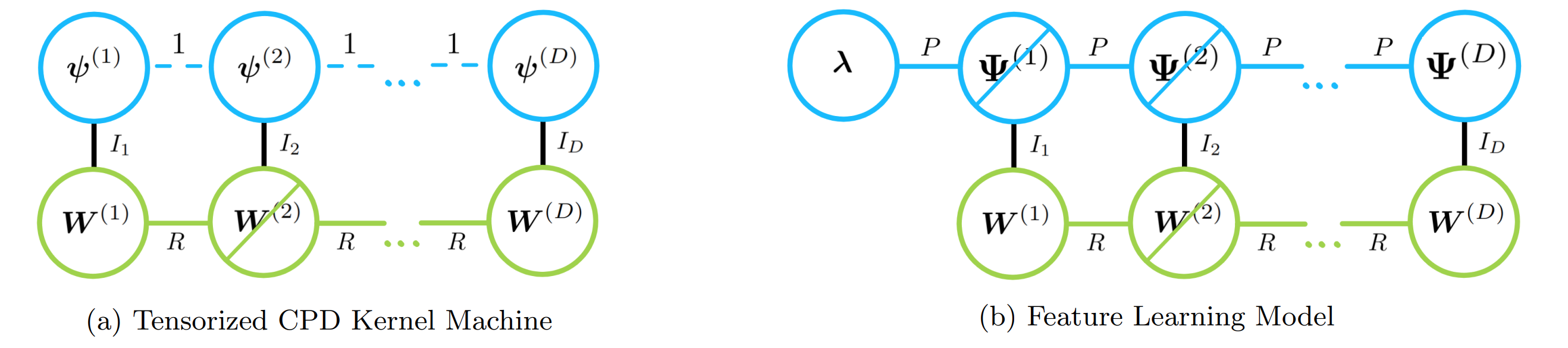
Summary
We introduce the Feature Learning (FL) model, where tensor-product features are represented using a learnable CP decomposition. The method jointly learns feature hyperparameters and model parameters with ALS optimization, achieving 3–5× faster training while maintaining comparable predictive quality.
Federated Privacy-Preserving Collaborative Filtering For On-Device Next App Prediction
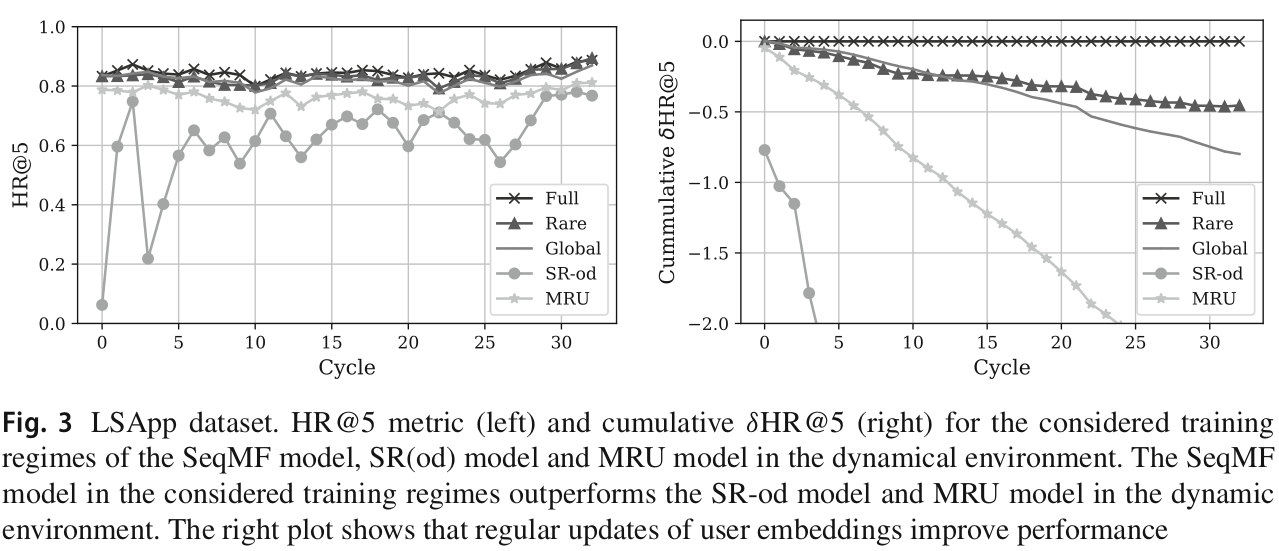
Summary
In this study, we propose a novel SeqMF model to solve the problem of predicting the next app launch during mobile device usage. We modify the structure of the classical matrix factorization model and update the training procedure to sequential learning. Since the data about user experience are distributed among devices, the federated learning setup is used to train the proposed sequential matrix factorization model. One more ingredient of our approach is a new privacy mechanism that guarantees the protection of the sent data from the users to the remote server. To demonstrate the efficiency of the proposed model, we use publicly available mobile user behavior data. We compare our model with sequential rules and models based on the frequency of app launches. Our experiments show that the proposed model provides comparable quality with other methods different environments.
Dynamical Collaborative Filtering Recommender System
Summary
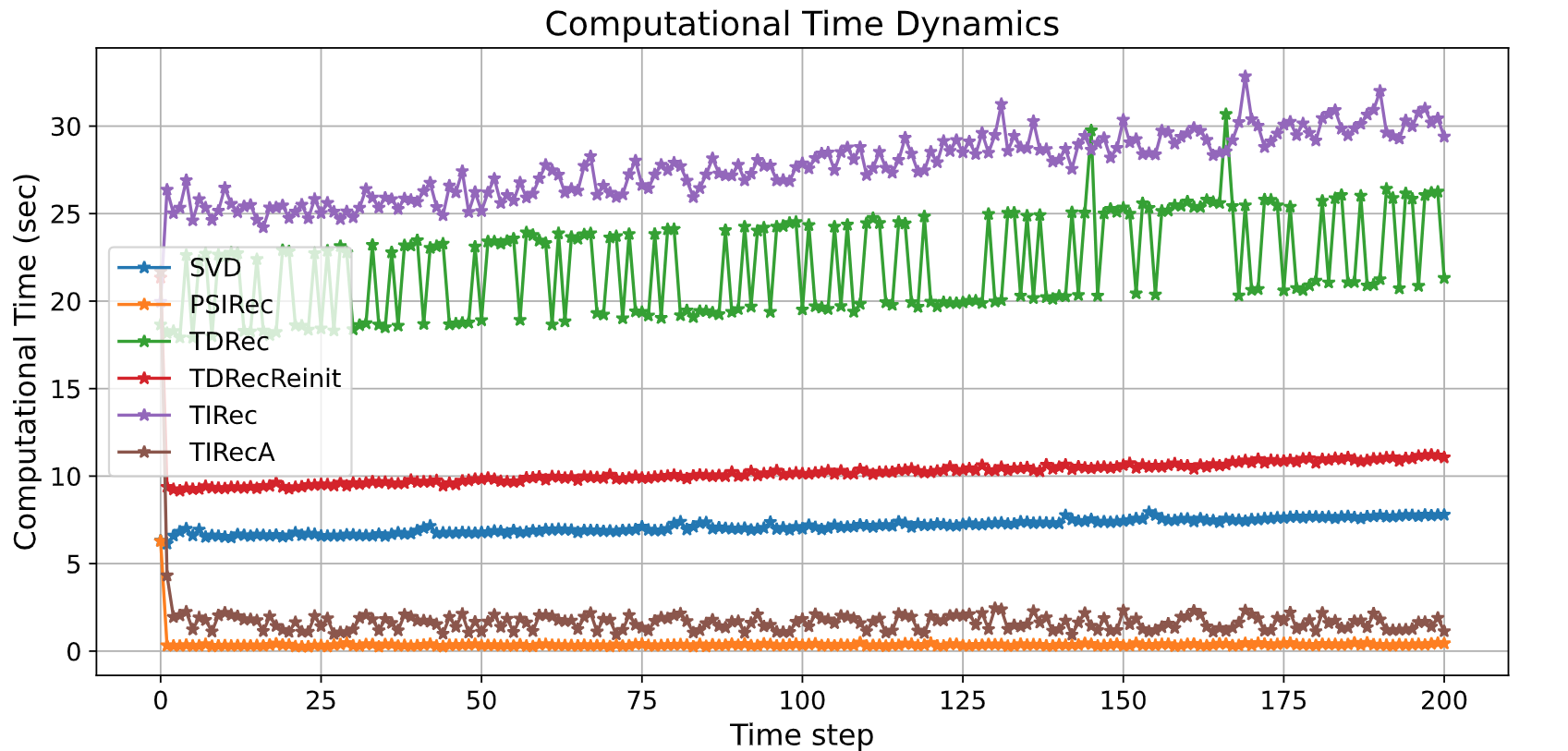
In production applications of recommender systems, a continuous data flow is used to update models in real-time. Many recommender models require complete retraining to adapt to new data. In this work, we introduce a novel collaborative filtering model for sequential problems, called the Tucker Integrator Recommender (TIRecA). TIRecA efficiently updates its parameters using only new data segments, allowing for the incremental addition of new users and items to the recommender system. To demonstrate the effectiveness of the proposed model, we conducted experiments on four publicly available datasets: MovieLens 20M, Amazon Beauty, Amazon Toys and Games, and Steam. Our comparison with general matrix- and tensor-based baselines, in terms of prediction quality and computational time, reveals that TIRecA achieves comparable prediction accuracy while being 10–20 times faster in training time.
MEKER: Memory Efficient Knowledge Embedding Representation for Link Prediction and Question Answering
Summary
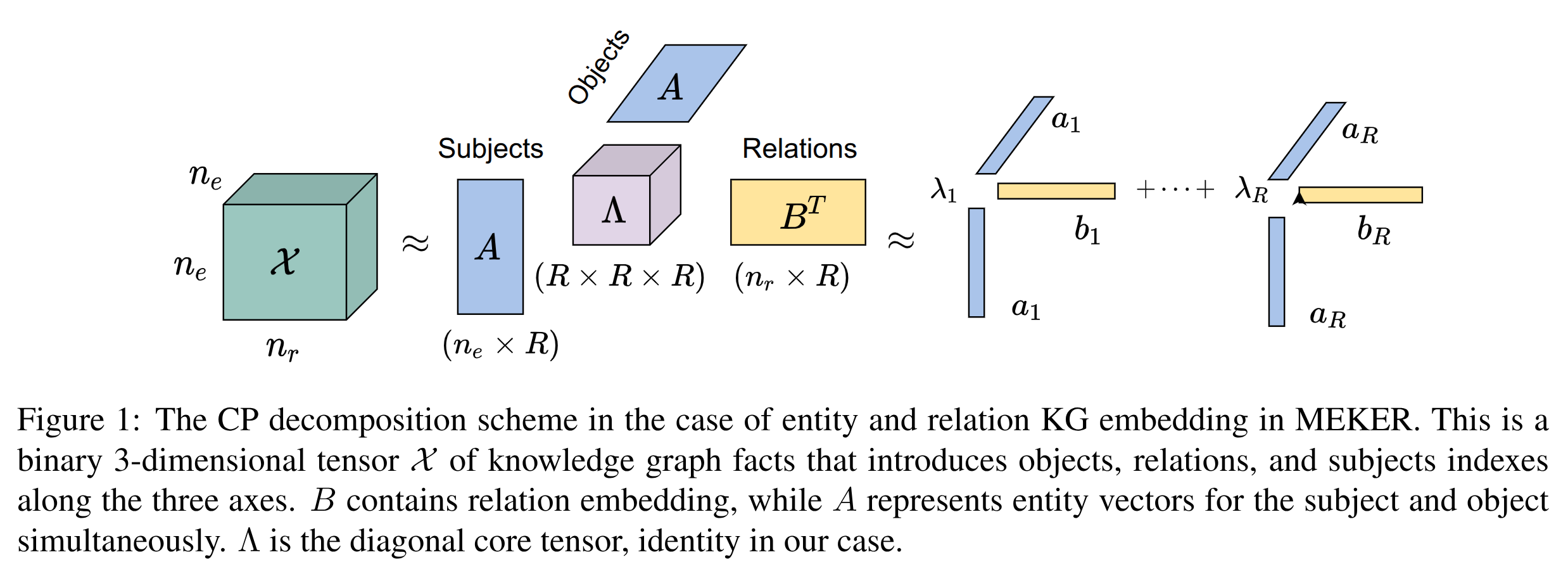
Knowledge Graphs (KGs) are symbolically structured storages of facts. The KG embedding contains concise data used in NLP tasks requiring implicit information about the real world. Furthermore, the size of KGs that may be useful in actual NLP assignments is enormous, and creating embedding over it has memory cost issues. We represent KG as a 3rd-order binary tensor and move beyond the standard CP decomposition (Hitchcock, 1927) by using a data-specific generalized version of it (Hong et al., 2020). The generalization of the standard CP-ALS algorithm allows obtaining optimization gradients without a backpropagation mechanism. It reduces the memory needed in training while providing computational benefits. We propose a MEKER, a memory-efficient KG embedding model, which yields SOTA-comparable performance on link prediction tasks and KG-based Question Answering.